-
友情链接:
Powered by 上海股票配资精选网站_股票配资手机操作_股票配资开户资料 @2013-2022 RSS地图 HTML地图

原标题:最强开源大模型深夜炸场! Llama 3 王者归来,直逼 GPT-4, 马斯克点赞
没有出乎太多意外,Meta 带着号称「有史以来最强大的开源大模型」Llama 3 系列模型来「炸街」了。
具体来说,Meta 本次开源了 8B 和 70B 两款不同规模的模型。
Llama 3 8B:基本上与最大的 Llama 2 70B 一样强大。
Llama 3 70B: 第一档 AI 模型,媲美 Gemini 1.5 Pro、全面超越 Claude 大杯
以上还只是 Meta 的开胃小菜,真正的大餐还在后头。在未来几个月,Meta 将陆续推出一系列具备多模态、多语言对话、更长上下文窗口等能力的新模型。
其中,超 400B 的重量级选手更是有望与 Claude 3 超大杯「掰手腕」。

又一 GPT-4 级模型来了,Llama 3 开卷
与前代 Llama 2 模型相比,Llama 3 可谓是迈上了一个新的台阶。
得益于预训练和后训练的改进,本次发布的预训练和指令微调模型是当今 8B 和 70B 参数规模中的最强大的模型。
同时后训练流程的优化显著降低了模型的出错率,增强了模型的一致性,并丰富了响应的多样性。
扎克伯格曾在一次公开发言中透露,考虑到用户不会在 WhatsApp 中向 Meta AI 询问编码相关的问题,因此 Llama 2 在这一领域的优化并不突出。
而这一次,Llama 3 在推理、代码生成和遵循指令等方面的能力取得了突破性的提升,使其更加灵活和易于使用。
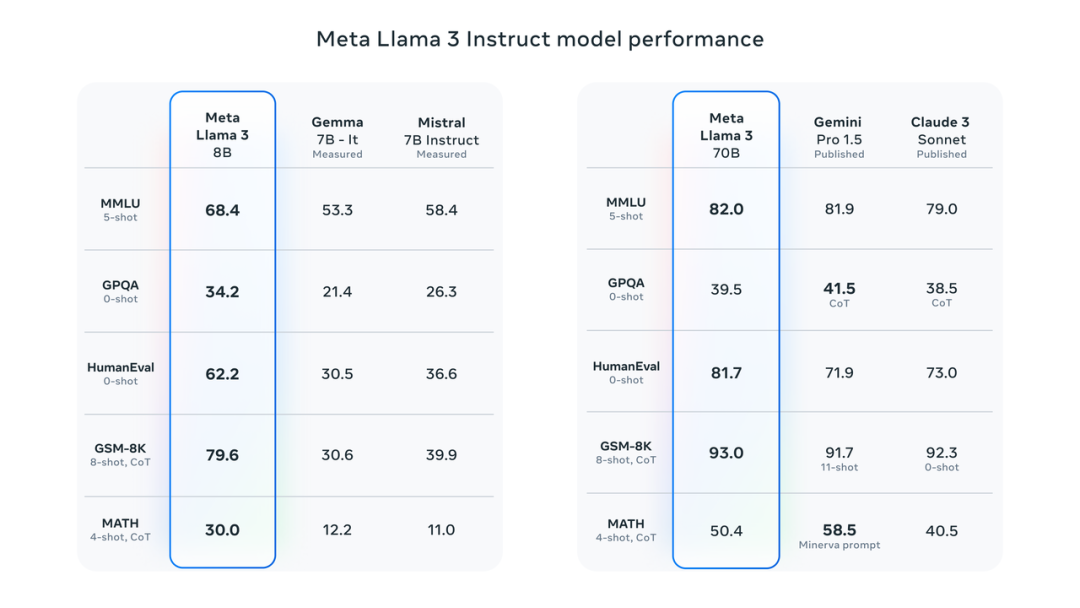
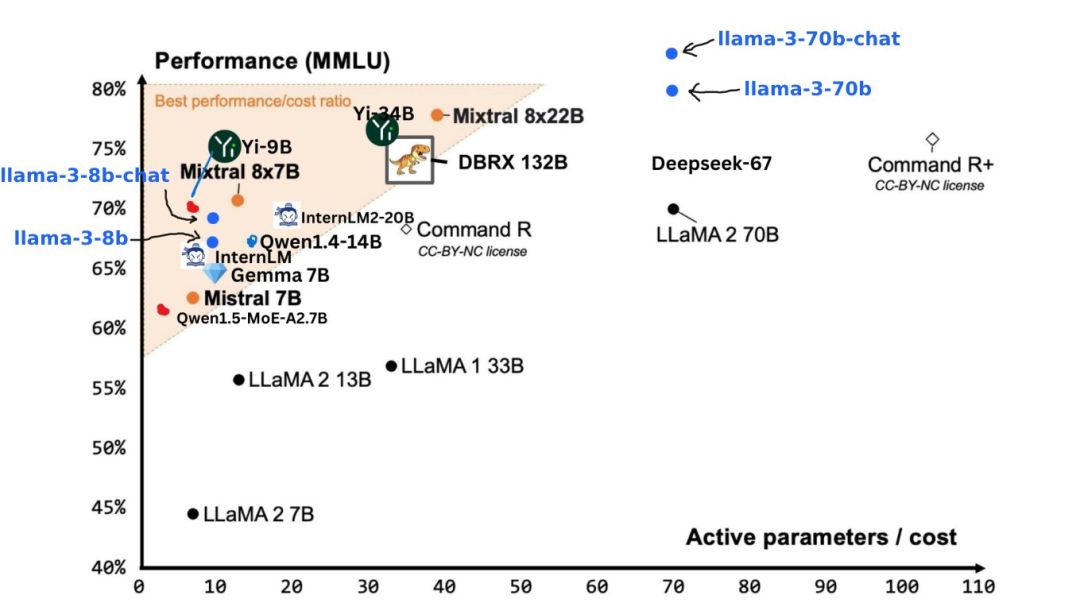
基准测试结果显示,Llama 3 8B 在 MMLU、GPQA、HumanEval 等测试的得分远超 Google Gemma 7B 以及 Mistral 7B Instruct。用扎克伯格的话来说,最小的 Llama 3 基本上与最大的 Llama 2 一样强大。
Llama 3 70B 则跻身于顶尖 AI 模型的行列,整体表现全面碾压 Claude 3 大杯,与 Gemini 1.5 Pro 相比则是互有胜负。
为了准确研究基准测试下的模型性能,Meta 还特意开发了一套新的高质量人类评估数据集。
该评估集包含 1800 个提示,涵盖 12 个关键用例:寻求建议、头脑风暴、分类、封闭式问答、编码、创意写作、提取、塑造角色、开放式问答、推理、重写和总结。
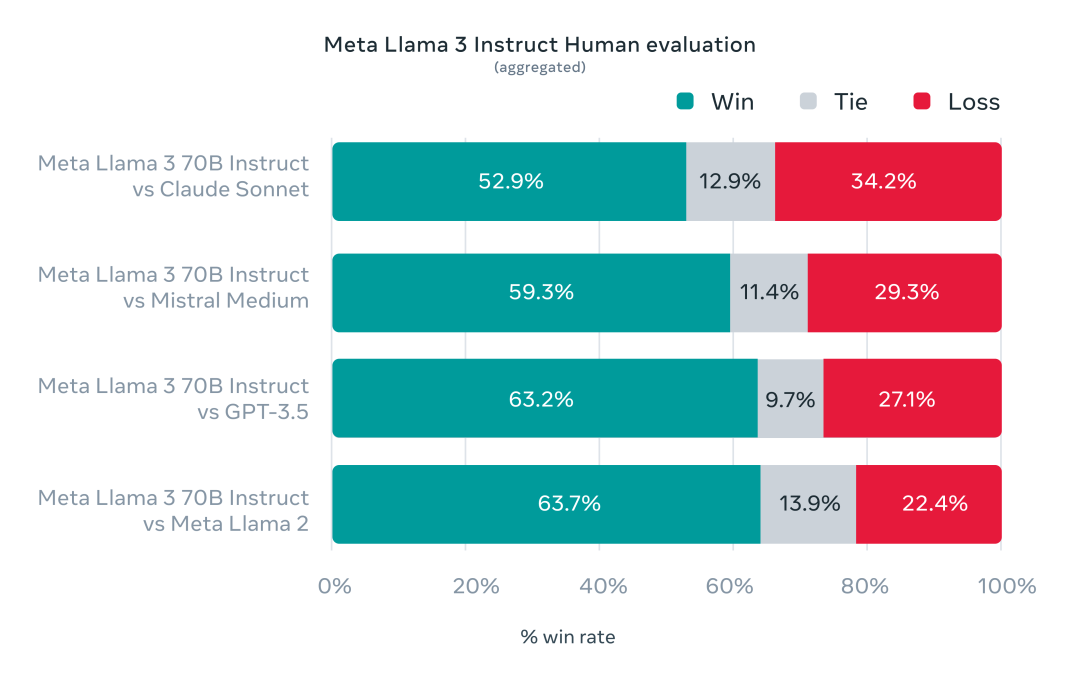
出于避免 Llama 3 在此评估集上出现过度拟合,Meta 甚至禁止他们的研究团队访问该数据集。在与 Claude Sonnet、Mistral Medium 和 GPT-3.5 的逐一较量中,Meta Llama 70B 都以「压倒性胜利」结束了比赛。
据 Meta 官方介绍,Llama 3 在模型架构上选择了相对标准的纯解码器 Transformer 架构。与 Llama 2 相比,Llama 3 进行了几项关键的改进:
使用具有 128K token 词汇表的 tokenizer,可以更有效地编码语言,从而显著提升模型性能
在 8B 和 70B 模型中都采用分组查询注意力 (GQA),以提高 Llama 3 模型的推理效率
在 8192 个 token 的序列上训练模型,使用掩码来确保自注意力不会跨越文档边界。
训练数据的数量和质量是推动下一阶段大模型能力涌现的关键因素。
从一开始,Meta Llama 3 就致力于成为最强大的模型。Meta 在预训练数据上投入了大量的资金。 据悉,Llama 3 使用从公开来源收集的超过 15T 的 token,是 Llama 2 使用数据集的七倍,其中包含的代码数据则是 Llama 2 的四倍。

考虑到多语言的实际应用,超过 5% 的 Llama 3 预训练数据集由涵盖 30 多种语言的高质量非英语数据组成,不过,Meta 官方也坦言,与英语相比,这些语言的性能表现预计是稍逊一筹。
为了确保 Llama 3 接受最高质量的数据训练,Meta 研究团队甚至提前使用启发式过滤器、NSFW 筛选器、语义重复数据删除方法和文本分类器来预测数据质量。
值得注意的是,研究团队还发现前几代 Llama 模型在识别高质量数据方面出奇地好,于是让 Llama 2 为 Llama 3 提供支持的文本质量分类器生成训练数据,真正实现了「AI 训练 AI」。
除了训练的质量,Llama 3 在训练效率方面也取得了质的飞跃。
Meta 透露,为了训练最大的 Llama 3 模型,他们结合了数据并行化、模型并行化和管道并行化三种类型的并行化。
在 16K GPU 上同时进行训练时,每个 GPU 可实现超过 400 TFLOPS 的计算利用率。研究团队在两个定制的 24K GPU 集群上执行了训练运行。

为了最大限度地延长 GPU 的正常运行时间,研究团队开发了一种先进的新训练堆栈,可以自动执行错误检测、处理和维护。此外,Meta 还极大地改进了硬件可靠性和静默数据损坏检测机制,并且开发了新的可扩展存储系统,以减少检查点和回滚的开销。
这些改进使得总体有效训练时间超过 95%,也让 Llama 3 的训练效率比前代足足提高了约 3 倍。
开源 VS 闭源
作为 Meta 的「亲儿子」,Llama 3 也顺理成章地被优先整合到 AI 聊天机器人 Meta AI 之中。
追溯至去年的 Meta Connect 2023 大会,扎克伯格在会上正式宣布推出 Meta AI,随后便迅速将其推广至美国、澳大利亚、加拿大、新加坡、南非等地区。
在此前的采访中,扎克伯格对搭载 Llama 3 的 Meta AI 更是充满信心,称其将会是人们可以免费使用的最智能的 AI 助手。
我认为这将从一个类似聊天机器人的形式转变为你只需提出一个问题,它就能给出答案的形式,你可以给它更复杂的任务,它会去完成这些任务。

当然,Meta AI 若是「 尚未在您所在的国家/地区推出」,你可以采用开源模型最朴素的使用渠道——全球最大的 AI 开源社区网站 Hugging Face。
Perplexity、Poe 等平台也迅速宣布将 Llama 3 集成到平台服务上。

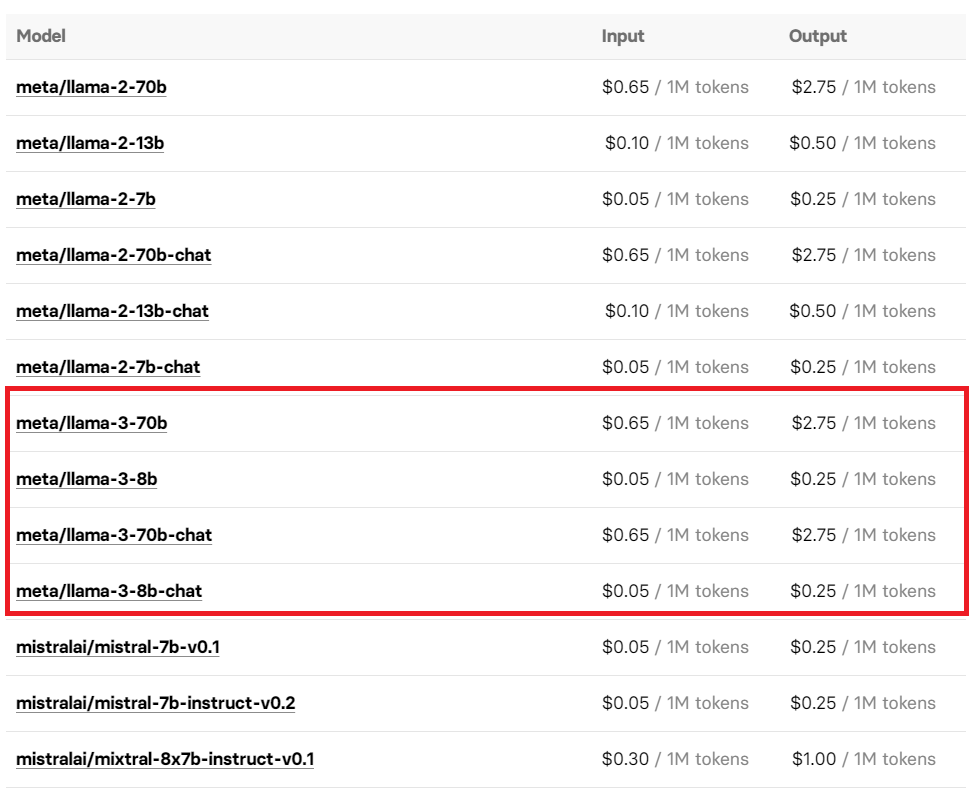
你还可以通过调用开源模型平台 Replicate API 接口来体验 Llama 3,其使用的价格也已经曝光,不妨按需使用。
有趣的是,在 Meta 官宣 Llama 3 前,有眼尖的网友发现微软的 Azure 市场偷跑 Llama 3 8B Instruct 版本,但随着消息的进一步扩散,当蜂拥而至的网友再次尝试访问该链接时,得到的只有「404」的页面。
Llama 3 的到来,正在社交平台 X 上掀起一股新的讨论风暴。
Meta AI 首席科学家、图灵奖得主 Yann LeCun 不仅为 Llama 3 的发布摇旗呐喊,并再次预告未来几个月将推出更多版本。就连马斯克也现身于该评论区,用一句简洁而含蓄的「Not bad 不错」,表达了对 Llama 3 的认可和期待。
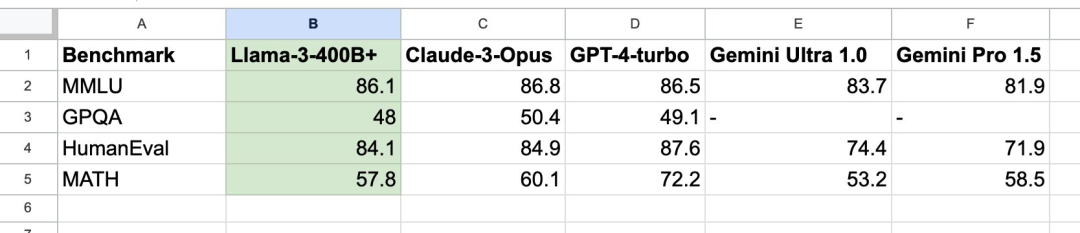
英伟达高级科学家 JIm Fan 则将注意力投向了即将推出的 Llama 3 400B+,在他看来,Llama 3 的推出已经脱离了技术层面的进步,更像是开源模型与顶尖闭源模型并驾齐驱的象征。
从其分享的基准测试可以看出,Llama 3 400B+ 的实力几乎媲美 Claude 超大杯、以及 新版 GPT-4 Turbo,虽然仍有一定的差距,但足以证明其在顶尖大模型中占有一席之地。
今天恰逢斯坦福大学教授,AI 顶尖专家吴恩达的生日,Llama 3 的到来无疑是最特别的庆生方式。
不得不说,如今的开源模型当真是百花齐放,百家争鸣。
今年年初,手握 35 万块 GPU 的扎克伯格在接受 The Verge 的采访时描绘了 Meta 的愿景——致力于打造 AGI(通用人工智能)。
与不 open 的 OpenAI 形成鲜明对比,Meta 则沿着 open 的开源路线朝 AGI 的圣杯发起了冲锋。
正如扎克伯格所说,坚定开源的 Meta 在这条充满挑战的征途中也并非毫无收获:
我通常非常倾向于认为开源对社区和我们都有好处,因为我们会从创新中受益。
在过去的一年中,整个 AI 圈都在围绕开源或闭源的路线争论不休, 甚至亲自下场的马斯克也通过开源 Grok 1.0 的方式给全世界打了个样。
如今 这场辩论,已经超越了技术层面的优劣比较,触及了 AI 未来发展的核心方向。
前不久,一些观点称开源模型将会越来越落后,如今 Llama 3 的到来,也给了这种悲观的论调一记响亮的耳光。
然而,尽管 Llama 3 为开源模型扳回一局,但这场关于开源与闭源的辩论还远未结束。
毕竟暗中蓄势待发的 GPT-4.5/5 也许会在今年夏天,以无可匹敌的性能为这场旷日持久的争论画上一个句号。
Powered by 上海股票配资精选网站_股票配资手机操作_股票配资开户资料 @2013-2022 RSS地图 HTML地图